Teaching a GAN What Not to Learn
イントロ
- GAN (Generative adversarial networks)の学習はdivergenceの最小化に等しい
- 最適なgeneratorは生成されたデータと真のデータの分布の違いを最小化するもの
- 真のデータの分布を\(p_d\), 生成したデータの分布 \(p_g\)とおく
- LSGANではdiscriminatorを回帰モデルとする
- 生成されたデータにラベル a, 真のデータにラベル bを付与
- Generatorはラベルcに分類されるようなデータを生成する
- LSGANにおいて最適なgeneratorは \(2p_d\)と \(p_d+p_g\)の Pearson-$\chi^2$ 誤差を最小化するようなものに相当
- Conditional GANはGANを教師ありに拡張したもの
- Generatorとdiscriminator両方にクラスラベルを入力
- それ以外のアプローチとしてはデータを正負に分け識別するものがある
- Metric learningやrepresentation learningではサンプル間の距離をニューラルネットの学習に使う
- Contrastive lossはサンプル間の類似度を計算し似ているものには正のラベル, 似ていないものに負のラベルを付す
- Triplet lossでは正のクラスからの距離を最小化&負のクラスからの距離を最大化するような学習を行う
- Complementary CGAN (CCGAN)は補完的なラベルがついているサンプルを学習する
- Generative positive-unlabelled learning (GenPU)は半教師ありGAN
- 正もしくは負のラベルあり+ラベルなしデータを入力とし, 正のラベルなしデータを負のデータから区別することを目的とする
- 一般的なGANは適当なgenerator見つけるのをゴールとしているが, GCGANやGenPUの最終目的は適当なdiscriminatorを見つけること
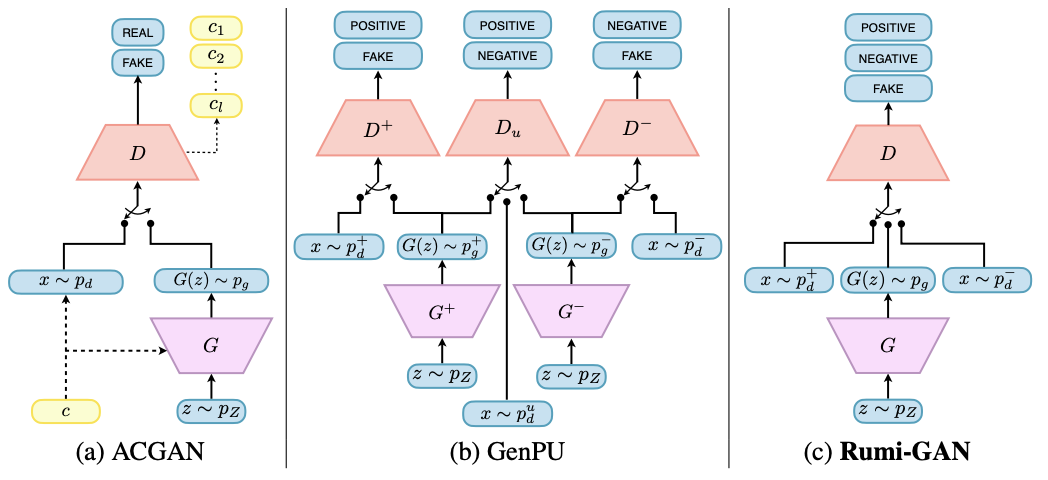
提案手法
- 本研究は詩人ルーミーの”The art of knowing is knowing what to ignore”という言葉に動機づけられたもの
- 本稿では学習”しない”負のサンプルをモデルに与える
- 具体的にはgeneratorの出力を望ましいサンプルと望ましくないサンプルに分け, それぞれに異なる重み付け
- こういったフレームワークを”Rumi”と呼ぶ
- Rumi設定下でSGANとLSGANを定式化する
- Rumi-SGANのdiscriminatorの損失関数は (a) 正ラベルサンプル(b) 生成サンプル (c) 負のクラスからのサンプル のクロスエントロピー
- \(p_g\)が非負&積分が1という制約も考慮
- ラグラジアンは式(2)で書ける
- Rumi-LSGANは(a) 正サンプルのラベル \(b^+\) (b) 負ラベルのラベル \(b^-\) (c) generatorからのラベル \(a\)とdiscriminatorの出力の二乗誤差を最小化
- 同時にgeneratorは生成されたサンプルに対して \(D({\bf x})\)と \(c\)の二乗誤差を最小化する
- 提案手法は教師なし学習における少数クラスの問題に対処できる
- ベンチマークデータを使った実験でGANに比べ低いFID (Fréchet Inception Distance)スコアを達成
実験
- 4つのデータセットを使用
- FIDスコアで生成した画像の尤もらしさを評価
- 学習した分布の多様さを評価するため, Precision-Recall (PR)でも評価
- MNISTデータについて, まずは5つの偶数のクラスに正, 奇数のクラスに負ラベルを付与
- LSGANは正例のみ用いて学習
- ACGAN, Rumi-LSGANはどちらも使用
- 図2(a)-(c)は生成した画像を比較したもの
- 提案手法のRumi-LSGANがよりシャープな画像を生成
- 負例の学習を避けることができるためと考察できる
- 次に正負がかぶっているMNISTデータを作成
- 1, 2, 4, 5, 7, 9に正ラベルを, 0, 2, 3, 6, 8, 9に負ラベルを付与
- 図2(d)-(f)に結果を図示
- 正負のラベルに重複があるにも関わらずRumi-LSGANは正のクラスに属した数字のみを学習できている
- 図3はFIDとPRカーブを比較したもの
- バンドは10回学習した際の幅
- Rumi-LSGANはより低いFIDの値に収束している
- ACGANはgeneratorが複雑な構造をしているため収束が遅い
- 最後に少数クラスの学習を評価
- MNISTデータで5以外の数字を負例とする
- 5のうち少数のサンプルに正のラベルを付与
- 図4(a)を見るとRumi-LSGANは5の画像のみを正しく生成できている