KDD 2021 Accepted Paper List with Links
国際会議KDD2021の事前準備メモ
Research Track Papers
A Graph-based Approach for Trajectory Similarity Computation in Spatial Networks
Peng Han (KAUST); Jin Wang (UCLA); Di Yao (Institute of Computing Technology, Chinese Academy of Sciences); Shuo Shang (KAUST); Xiangliang Zhang (King Abdullah University of Science and Technology, Saudi Arabia)
Accurate Multivariate Stock Movement Prediction via Data-Axis Transformer with Multi-Level Contexts
Jaemin Yoo (Seoul National University); Yejun Soun (Seoul National University); Yong-chan Park (Seoul National University); U Kang (Seoul National University)
- 株価の予測は重要なタスク
- 難しいが報酬も大きい
- 株価はわかりやすいパターンがなくランダムに変化する
- 1%の予測精度の向上でも莫大な利益を生む
- 今日までの株価の履歴 \({p_t}_{t\leq T}\)から明日の株価が今日より上がる (\(p_{T+1}>p_{T}\))か下がる (\(p_{T+1}<p_{T}\))かを当てる
- 株価は互いに強く相関する
- 既存手法は一変数のモデルと複数変数のモデルの2種類
- 一変数のモデルは株価同士の相関を扱うことができない
- 複数変数のモデルは相関の時間変化を捉えることができない
- 時変する相関を事前知識なしでモデル化する手法を提案
- 提案手法は3つのアイデアからなる
- Time-axis attention: 各々の株価について過去の履歴を集約 (Attention LSTM)
- Context aggregation: 個々の文脈をまとめる
- Data-axis attention: Transfomerを用いて相関を学習
- 実験では6つのデータを用い, 精度とそれによる利益の評価, アテンション結果の可視化, Ablation studyを行った
- 先行研究と同じ特徴量を使用
ACE-NODE: Attentive Co-Evolving Neural Ordinary Differential Equations PDF
Sheo Yon Jhin (Yonsei University); Minju Jo (Yonsei University); TaeYong Kong (Yonsei University); Jinsung Jeon (Yonsei university); Noseong Park (Yonsei University, Korea)
- Neural ODE (NODE)は様々なタスクにおいて適用が進んでいる
- NODEの拡張として, augumentationを行う手法, 正則化を入れる手法などが提案されている
- しかしNODEにアテンションのコンセプトを導入したものはない
- 本研究では Attentive dual Co-Evolving NODE (ACE-NODE)を提案する
- 潜在ベクトルの時間発展 \({\bf h}(t)\)に加え, アテンションの時間発展 \({\bf a}(t)\)を考慮
- \({\bf h}(t)\)と \({\bf a}(t)\)が連動して時間発展すると仮定
- アテンションとしてペアワイズなものとエレメントワイズなものの2種類を考える
- 前者は時系列予測で, 後者は画像の分類タスクにおいてよく使われる
- ペアワイズなアテンションでは, \({\bf h}(t)\)の各次元の組み合わせ \(i\), \(j\)ごとにアテンションの値を学習する
- 例えば \({\bf h}(t)\)の最初の次元がAppleの株価, 二番目の次元がGoogleの株価と考えるとこれらの次元同士の関係性をアテンションで取り入れるのは自然な発想
- 画像の分類においては, \({\bf h}(t)\)は連続時間の特徴量マップを表す
- この場合 \({\bf a}(t)\)はエレメントワイズなアテンションであり, \({\bf h}(t)\)と掛け合わせて使う
- 時系列データと画像データを用いて実験を行った
- 画像分類タスクでは, MNIST, SVHN, CIFAR10を用い, ODE-Netや他の従来の畳み込みネットワークと比較する
- 時系列予測では, 気候データセットと病院データセットを用いた
Adaptive Transfer Learning on Graph Neural Networks
Xueting Han (Microsoft Research Asia); Zhenhuan Huang (Beihang University, Microsoft Research Asia); Jing Bai (Microsoft); Bang An (University of Maryland, College Park; Microsoft Research Asia)
Attentive Heterogeneous Graph Embedding for Job Mobility Prediction
Le Zhang (University of Science and Technology of China) et al.
- 転職の予測は今後ますます重要に
- 伝統的には転職に効く特徴量を持ってきて回帰する手法が用いられてきた
- 最近は過去の転職履歴を用いたニューラルネットに基づく手法が提案されている
- しかしこれらの手法は会社間, 役職間のマクロな関係を考慮していない
- 個人の転職履歴 \(\mathcal{J}(u)=\{\mathcal{J}_1,...,\mathcal{J}_L \vert u \}\)と会社-役職ネットワークが与えられた下で次の転職 (会社, 役職, 期間)を予測する
- LinkedINのデータを使用
- 提案手法は会社-役職ネットワークを入力とするattentive graph embedding, 個人の転職履歴を読み込むsequential module (Dual-GRU)からなる
- 社歴, 職歴をgraph embeddingで学習した各会社, 各役職の潜在ベクトルを用いて書き換え, それに期間を結合したものをDual-GRUの入力として使う
Auditing for Diversity Using Representative Examples
Vijay Keswani (Yale University); L. Elisa Celis (Yale University)
Causal models for Real Time Bidding with repeated user interactions PDF
Martin Bompaire (Criteo); Benjamin Heymann (Criteo); Alexandre Gilotte (Criteo)
- Demand Side Platform (DSP)におけるReal Time Bidding (RTB)ではユーザがサイトを訪問する度にオークションが行われる
Causal Understanding of Fake News Dissemination on Social Media PDF
Lu Cheng (Arizona State University); Ruocheng Guo (Arizona State University); Kai Shu (Illinois Institute of Technology); Huan Liu (Arizona State University)
- どんなユーザがフェイクニュースをシェアしやすい (susceptibilityが高い)のか分析する
- ユーザがフェイクニュースをシェアした場合にそのユーザとニュースの間にエッジがあると見做す
- その際, バイアスを考慮する必要がある
- とあるユーザ \(u\)がとあるフェイクニュース \(i\)を拡散する確率 \(Y_{ui}\)はそのユーザのニュースへの興味 \(R_{ui}\in {0,1}\)とそもそもそのニュースを目にする確率 \(O_{ui}\in {0,1}\)の積で決まる
- ユーザとニュースの二項グラフを考える
- 観測されたポジティブな相互作用と観測されていないネガティブな相互作用がある
- 選択バイアスを緩和するため, 傾向スコアによる重み付け (IPS)を使うアプローチを提案
- この文脈において, 傾向=フェイクニュースが目に触れる確率 \(\theta_{ui}=P(O_{ui}=1)=P(Y_{ui}=1\vert R_{ui}=1)\)
- 傾向スコア \(\theta_{ui}\)について三通りのモデル化を提案
- 一つ目はニュースのシェアされやすさに基づく傾向スコア
- 二つ目はユーザとニューズのシャアしやすさ, されやすさに基づくスコア
- 三つ目はニュースの内容を入力とするニューラルネット
- 最終的にはフェイクニュースをシェアしやすいユーザの特徴を特定したいので, 年齢, フォロワー数等のプロフィール \({\bf a}_u\)を入力として使う
- 各ユーザのsusceptibilityをそのユーザがシェアしたニュースのうちフェイクニュースが占める割合 \(B_u=n_{fake}^u/(n_{fake}^u+n_{true}^u)\)で定義
- 単純には \(B_u\)をプロフィール \({\bf a}_u\)で回帰すればよいが, 今は因果関係が知りたい
- 提案手法ではまず二項グラフに先ほど定義した傾向スコアでIPWをかける
- IPW済みのデータについて回帰モデルによるフィッティングを行う
- 実験では二つのデータを使用
- まずニュースのシェア予測の精度を評価
- フォロワー数, アカウントがオフィシャル認証されているかどうかがフェイクニュースの拡散に影響するプロフィールとして推定された
- 認証されているアカウントがsusceptibleでないのは自然
DARING: Differentiable Causal Discovery with Residual Independence
Yue He, Peng Cui, Zheyan Shen, Renzhe Xu, Furui Liu, Yong Jiang
- 複数の変数間の因果関係の発見は様々な分野で重要なタスク
- \(d\)個の変数が \(n\)サンプル与えられた下で \(d\)個の変数の生成過程を表すDAGを推定する
- これは本来NP-Hardな問題だが, これを連続最適化の枠組みで扱うアプローチ提案されている
- 変数間の関係に線形性を仮定し, このタスクを線形回帰モデル \(X=WX+\epsilon\)のパラメータ \(W\)の推定に帰着させる
- 損失関数を \(F(W) = \vert X - X W\vert^2 + \lambda \vert W\vert_1\)で定義し, \(W\)がDAGとなるような学習をすればよい
- \(h(W) = tr(e^{(W \circ W)} -d)\)が成り立つ時に \(W\)がDAGとなることが先行研究で示されている
- \(F(W)\)を最適化するときに \(h(W)\)を満たすように \(W\)を学習することで \(W\)がDAGになる
- しかし, この手法が実データを用いた実験環境において必ずしも正しい因果グラフを学習できない
- 本研究では, それが過剰再構成問題に起因していることを示した
- 敵対的な方法で明示的な残差独立性制約を課すことで, 新しい微分可能な手法DARINGを提案した
- シミュレーションと実データを用いた広範な実験の結果, 提案手法は外部ノイズの不均一性に影響されず, 因果関係の発見性能を大幅に向上させることができた
Choice Set Confounding in Discrete Choice PDF
Kiran Tomlinson (Cornell University); Johan Ugander (Stanford University); Austin R Benson (Cornell University)
イントロ
- 個人の選択は環境政策, マーケティング, ウェブ検索, 推薦システム等幅広い応用で重要
- 離散選択モデルは個人が選択集合の中から代替案を選択する事象を定式化するもの
- しかしこれらのモデルは選択集合の割り当てが推薦アルゴリズムで決まるという事実を考慮していない
- この論文では, 個人の嗜好に依存して選択集合が割り当てられる問題を選択集合の交絡と呼ぶ
- 離散選択においてはおとり効果, 妥協効果などの知見が確認されているが, 選択集合の交絡によってそれらの真の効果を見誤る可能性がある
- 本研究では選択集合の交絡が問題になるケースを分析
- また, 離散選択モデルの評価でよく使われる2つの交通データセットにおいて, 選択集合の交絡の存在を示す証拠を提示した
- さらに選択集合の交絡に対処するため, 2つの因果モデルを構築した
背景技術
- ここではそれぞれの離散選択が行われる確率を考え, その確率を最大にするようなパラメ-タを最尤法で推定する離散選択モデルを考える
- 選択集合 \(C\)と選択 \(i\)のペア \((C,u)\)の収集データ \(D\)が与えられた下で個人 (選択者) \(a\)が選択集合 \(C\)から要素 \(i\)を選ぶ確率を \(P(i\vert a,C)\)でモデル化
- 確率分布関数 \(P(\cdot)\)は一般的に選択集合 \(C\)の中の要素 \(i\)の効用 \(u_i(C,a)\)を用いてソフトマックス関数 \(Pr(i\vert a,C)=\exp{(u_i(C,a))}/\sum_j\exp{(u_j(C,a))}\)でモデル化される
- \(u_i(C,a)=u_i\)とした場合, これはシンプルなロジットモデルに一致する
- 他にも個人の特徴量 \({\bf x}_{\bf a}\), 要素 \(i\)の特徴量 \({\bf y}_i\)が観測できるケースもある
- その場合, 効用 \(u_i(C,a)\)を \({\bf x}_{\bf a}\), \({\bf y}_i\)を用いた形 (表1参照)で記述することでこれらの特徴量を考慮することができる
- これらの定式化は選択集合と要素が独立であるという IIAの仮定に基づいている
- \(u_i(C,a)\)をモデル化する際, 要素 \(i\)だけでなく選択集合 \(C\)の情報も使うアプローチが提案されている (表2)
提案手法
- 本論文では因果推論におけるIPWのアイデアを離散選択モデルに導入する
- IPWは個々の共変量が与えられた場合の各治療割り当ての確率を記述した傾向スコアを推定するもの
- 真の確率 \(Pr(T_i\vert X_i)\)は未知なので, 代わりに「傾向スコア」 \(\hat{Pr} (T_i \vert X_i)\)を観測データから学習する
- 通常ロジスティック回帰が用いられる
- 傾向スコアは平均的な治療効果の推定や学習データの重み付けに使われる (今回は後者)
- 各サンプルを各々の傾向スコアの逆数で重み付けすることで, 治療が共変量と関係なくランダムに割り当てられた擬似的な場合のデータを構築できる
- 偏りのない離散選択モデルを学習するためには, 選択者に依存しない選択集合が必要
- そのため, IPWを用いて擬似データセットを作成し, その擬似データセットを用いて離散選択モデルの学習を行う
- そのために 選択セットの割り当て確率 \(Pr(C\vert a)\)をモデル化
- そして, 各サンプル \((i,a,C)\)を \(1/[\vert C_{\mathcal{D}}\vert Pr(C\vert a)]\)で置き換えることで擬似データセット \(\tilde{\mathcal{D}}\)を作成する
- これは単純に尤度に重み \(1/[\vert C_{\mathcal{D}}\vert Pr(C \vert {\bf x}_a])\)を掛け合わせることに等しい
- 今回は \(Pr(C\vert a)\)の代わりに \(Pr(C\vert {\bf x}_a)\)を使う
- そのために必要な仮定を図1に示す
Context-aware Outstanding Fact Mining from Knowledge Graphs
Yueji Yang (National University of Singapore); Yuchen Li (Singapore Management University); Panagiotis Karras (Aarhus University); Anthony Tung (NUS)
- ナレッジグラフから特筆すべき事実 (OF)を見つけるタスクに取り組む
- OFは(1) ターゲットのエンティティ (2) 属性と値のペア (事実) (3) ピアエンティティ からなる
- 例えばカラマ・ハリス (ターゲット)が女性初 (属性)の副大統領 (ピア)になった, など
- 既存のOFマイニング手法は以下の問題がある
- 文脈を考慮できない
- ドメイン特有の関係データに依存している
- 本研究ではナレッジグラフとターゲットの文脈が与えられた下でOFを出力するタスクに取り組む
- まず文脈のエンティティとターゲットとエンティティをつなぐパスを取得し, 間のノードを共有するエンティティを列挙
- 例えば文脈としてマイク・ペンス, ターゲットとしてカラマハリスが与えられた場合, 両者をつなぐハリス-副大統領-ペンスのパス, ハリス-アメリカの議員-ペンスを抽出
- アメリカの議員に紐づいているジョー・バイデン, ヒラリー・クリントンなどのノードをmatching node setとして保持しておく
- パスに含まれるノード同士の関連度をHoriontal relevance, matching node setに含まれるノード同士の関連度をVertical relevanceと定義
Coupled Graph ODE for Learning Interacting System Dynamics PDF
Zijie Huang (University of California, Los Angeles); Yizhou Sun (UCLA); Wei Wang (UCLA)
- 複数のエージェントから構成されるシステム (MAS)は時変グラフで表される
- 静的なグラフに対してはGNNが使われる
- 実際にはMASを記述するグラフは時間的に変化する (ノード間のリンクが出現したり消えたりする)
- 例1: 政党のイデオロギーの変化
- 例2: 交通グラフ
- これらの時間変化は連続的
- USにおけるコロナの発生データを考える
- ノードは州ごとの感染者数, エッジは州間の人流
- 感染者数の変化に応じた規制によってエッジの人流が変化し, また変化した人流によってノードの感染者数も変化する
- このようなエッジとノードのco-evolutionを考慮する必要がある
- ノードの軌跡の系列 \({X^1, X^2, ..., X^T}\)と隣接行列 \({A^1, A^2, ..., A^T}\)が与えられた下で未来の時刻におけるノードの軌跡 \(X^t (t>T)\)を予測する
- 既存手法のLG-ODEでは静的なグラフに対してVAEベースのODE solverを提案している
- VAEのエンコーダで初期状態の推論, 生成モデルで潜在状態 \(z^t_i\)の変化を学習, デコーダで実際の軌跡 \(x^t_i\)を予測する
- 提案手法でもLG-ODEと同じく3つの構成要素を仮定
- オブジェクト同士は強く相関しているため初期状態を同時に推論した方がよい
-> 時間グラフを作ってメッセージパッシングをかける (デコーダ) - 各々のオブジェクトについて潜在状態の遷移を生成するためself-attentionモデルを適用 (生成モデル)
- 生成した潜在状態の系列に基づいて実際の軌跡を予測 (エンコーダ)
- オブジェクト同士は強く相関しているため初期状態を同時に推論した方がよい
- デコーダ, エンコーダ, 生成モデルをELBOを用いてまとめて最適化
- 実験ではCOVID-19データ, ソーシャルネットワークのシュミレーションデータを使用
- 提案手法は長期予測で既存手法を上回る精度
- COVID-19の予測において移動制限をかけた場合のシュミレーションを実施
- 州間の移動を20%減らす, 州内の移動を20%減らす, 州人口が多い順に州間の移動を減らす, という3つのシナリオを想定
- 州内の移動を減らすシナリオで最も死者数が減少するという結果
- 州間の移動人数よりも州内の移動人数が多いのでこれは直感に合っている
Deep Learning Embeddings for Data Series Similarity Search
Qitong Wang (University of Paris); Themis Palpanas (University of Paris)
- Data series=ある次元に沿って並び替えられた点の系列
- ここで次元=時間, 角度, 位置, 質量, 頻度など様々
- 脳波 (EEG)データ, 地震データなど
- 系列の類似性の探索は分類, 異常検知など様々なタスクで重要
- 本研究では近似類似探索に取り組む
- 一番近いものではなく, ある程度近そうな系列を返すタスク
- 既存手法iSAXはPiecewise Aggregate Approximation (PAA)に基づく手法
- PAA近似の精度に依存する
- PAAはランダムウォーク系列のような系列ではよく働くがDeep1B系列のような変化が激しい系列に対してはうまくフィットしない
- 本研究ではPAAを深層学習で置き換える手法を提案
- 効率的で大規模データにも適用できる手法が望ましい
- Sum of Squares (SoS)制約と組み合わせたResNetを提案
- 提案手法の目的関数は近似性を評価する項と再構成の度合いを評価する項の二つの項からなる
- SoSは \(\sum_{i,j} M^2_{i,j}\)で定義
- ここで行列 \(M\)の列は系列, 行は場所
- 大規模データへの適用も見越してサンプリングに基づくアルゴリズムを提案
- 実験では3つの人工データと4つの実データを使用
- SoSによってtightnessが改善
Differentiable Pattern Set Mining PDF
Jonas Fischer (Max Planck Institute for Informatics); Jilles Vreeken (CISPA Helmholtz Center for Information Security)
イントロ
- 頻出パターンマイニングに取り組む
- パターンマイニングはある制約を満たすパターンでデータ中に高頻度に存在するものを全て列挙する
- ユーザによって定義された”おもしろさ”の閾値を超えるパターンを制限なく列挙するため, 膨大なパターンを出力してしまいがち
- 最近, パターンマイニングをモデル選択問題として再定式化し, 代表的なパターンの組を明示的に求めるアプローチが提案されている
- パターンの組の探索空間はパターン単体の探索空間よりもさらに大きく (特徴量次元の二重指数), 効率的な探索が難しい
- 既存手法はいずれもヒューリスティックな手法に頼っており, せいぜい数百程度の特徴量を持つデータにしか適用できない
- 全ゲノム関連研究 (GWAS), 数十万の特徴量からなる単一細胞系列のような最新の生物学的応用には適用できない
- 本研究では, これらの組み合わせに基づくアプローチの代わりに, 微分を用いたアプローチを提案する
- そのため, バイナリデータのための解釈可能なオートエンコーダ BinaPs (Binary Pattern Networks)を提案
- BinaPsはエンコーダ (隠れ層)とデコーダ (出力層)の2つの線形層から構成されている
- エンコーダとデコーダで重みを共有
- 学習時は通常通り連続値の重み \(W\)を使用
- フォワードパスにおいては \(W\)を離散化 (バイナリ化)した重み \(W_b\)を使用
- こうしておくと, \(W_b\)が共起関係を表す行列になる
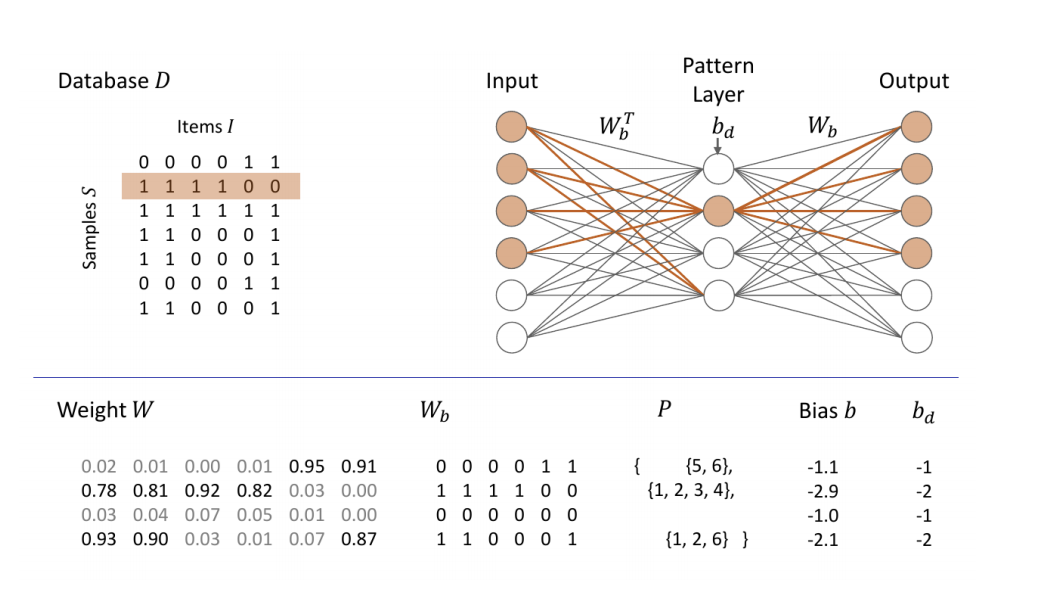
- 本研究では, データの疎性を考慮した再構成損失を提案している
- 提案手法は密度の高い生物学的データにも疎な金融取引データにも適用可能
Discrete Choice Models with Interpretable Context Effects
Kiran Tomlinson (Cornell University); Austin R Benson (Cornell University)
Deep Generative model for Spatial Networks
Xiaojie Guo (George Mason University); Yuanqi Du (George Mason University); Zhao Liang (Emory University)
- タンパク質構造, 脳のネットワーク, 交通ネットワークなど空間ネットワークは様々ある
- これらのネットワークは空間情報だけでなくネットワーク情報を含む
- 空間ネットワークの生成には画像や文章生成と同じ方法を適用できる
- ガウス分布から生成モデルで分布を生成し, その分布からのサンプリングで空間ネットワークを生成する
- しかしその際いくつか課題が出てくる
- 異なる空間ネットワークは異なるパターンを持つ (例えば脳ネットワークは回転普遍性を持つ)
- Disentangledな要素が大きく3つある
- 回転普遍性など空間に関するもの
- 空間情報とネットワーク情報の相関に関するもの (脳ネットワークの密度とノード間の距離は違いに相関している)
- ノード間の結合などネットワークに関するもの
- 本研究ではこの3つの要素に対応する3つの潜在ベクトル \(Z=(z_s, z_g, z_{sg})\)を導入する
- \(Z\)で条件づけられたDisentangledな分布 \(P(S,G\vert Z)\)を学習し, この分布からのサンプリングでネットワーク \(X=(S,G)\)を生成する
- \(S\), \(G\), \(Z\)の同時分布は \(P(S,G,z_s, z_g, z_{sg}))=P(z_s)P(z_g)P(z_{sg})P(S\vert z_s,z_{sg})P(G\vert z_g,z_{sg})\)のように分解できる
- \(P(z_{sg})P(S\vert z_s,z_{sg})\), \(P(G\vert z_g,z_{sg})\)は生成モデルで記述
- 事前分布 \(P(z_s),P(z_g),P(z_{sg})\)のモデル化が問題
- 本研究では \(P(z_s),P(z_g),P(z_{sg})\)を各々 \(S\)もしくは \(G\)の条件付き分布で近似し, \(S\), \(G\)に基づく生成モデルで分布
- 情報量の損失を抑えるため, Information bottleneck \(I_{sg}\)に制約 \(I_{sg}<C_{sg}\)を課す
- この制約を考慮するため, 2重の最適化アルゴリズムを提案
- \(I_{sg}\)が \(C_{sg}\)を超えたところでループを止める
- 実験では3つの実空間ネットワークデータを使用
- 再構成誤差などの定量評価に加え, Disentangledに関する定性評価も行なった
- 3種類の潜在ベクトルの値を変化させることで生成されるネットワークに違いが出ることを確かめた
- 1つ目の潜在ベクトルをいじるとノードの値が変化
- 2つ目の潜在ベクトルをいじると絶対位置が変化
- 3つ目をいじるとノード間の距離とエッジ数が変化
Efficient Data-specific Model Search for Collaborative Filtering PDF
Chen Gao (Tsinghua University); Quanming Yao (4Paradigm); Depeng Jin (Tsinghua University); Yong Li (Tsinghua University)
イントロ
- 強調フィルタリングのベンチマークデータは様々な応用から生じるもので, 形態, 規模, 分布などが様々
- 暗黙的なものと明示的なものの2つの代表的な形式がある
- データセットの規模 (大きいか小さいか)や分布 (密か疎か)も多様
- 素朴なMFやFISMに代表される行列分解は, 学習は容易だが表現力が限られているため, 複雑なユーザ・アイテム間の相互作用を捉えることができない
- 一方, ニューラルモデルは, データが十分な場合には優れた性能を発揮するが, 比較的小さいデータセットの場合にはうまくいかない
- この研究ではAutoMLを使ってCFモデルの探索を行うアプローチを提案する
- その際, (i) 適切な探索空間の設計 (ii) 効率的な探索を行う必要がある (データの性質が多様なため)
提案手法
- CFの重要な構成要素はユーザ・アイテム間の相互作用の評価
- この論文では相互作用関数を探索するone-shotアルゴリズムであるSIFをCFタスクに一般化
- 入力, エンコード, 表現学習, 相互作用の評価, 予測という5つのステージ各々で選択肢を設定する (表2参照)
- 例えば入力としてはユーザID \(\texttt{ID}\), 過去の履歴 \(\texttt{History}\)を用意
- 相互作用の評価関数として \(\texttt{multiply}\), \(\texttt{min}\), \(\texttt{max}\), \(\texttt{concat}\)を用意
- 埋め込みの次元, 学習率についても選択肢を用意しこれらも自動で学習する
- さらに効率的な探索を行うため, ランダムサーチとperformance predictorを組み合わせた探索アルゴリズムを構築
Energy-Efficient Models for High-Dimensional Spike Train Classification using Sparse Spiking Neural Networks PDF
Hang Yin (Worcestor Polytechnic Institute); John Lee (WPI); Xiangnan Kong (Worcester Polytechnic Institute); Thomas Hartvigsen (Worcester Polytechnic Institute); Sihong Xie (Lehigh University)
イントロ
- 時系列の分類は重要なタスク
- 時系列には急激な上昇 (スパイク)が含まれる
- スパイクのいい例は脳波
- 脳は約1,000億個の神経細胞 (ニューロン)からなるネットワークであり, 神経細胞間の情報伝達は活動電位 (スパイク)と呼ばれる信号の発射によって行われる
- スパイクをモデル化するための最も一般的な方法は, スパイクがあれば1, なければ0というスパイク列として捉えること
- 本研究ではスパイク列の分類に取り組む
- スパイク列の分類は従来の時系列の分類とは異なり, 入力と出力の両方にスパイク列を持つタスクである
- このようなタスクはヘルスケアや人の行動モニタリングにおいて重要
- スパイク列の分類に有効な手法としてスパイキングニューラルネットワーク (SNN)がある
- SNNは潜在変数 (膜)の値がある閾値を超えたら1 (発火), 超えなかったら0を返すモジュール (spiking neuron)を含む
- 一方, センサーシステムの小型化が進み, 高齢者介護用のウェアラブルセンサーやスマートフォン, 空中ロボットなど様々なスマートデバイスからスパイク列が収集可能になっている
- こういったセンサーデータの活用シーンとして, 例えば心拍数 (HR), 血圧 (BP)、酸素飽和度 (SpO2)などのセンサーデータから心臓病の予測をする等の応用が考えられる (図1)
- これらの機器は利用可能なエネルギーに制限があるため, 推論時の計算コストが低い手法が望ましい
- 計算コストの面から言うと, SNNは密なネットワークなため, 不必要な計算が多い
- SNNは元々脳の仕組みにインスパイアされたモデル
- 細胞神経間の相互作用は実際にはほとんどが無視できるということがわかっている→SNNも重みが小さい結合は無視してもいいのでは?
- 本論文では, スパースなSNNを提案する
- 具体的にはSNNの各層の重み \({\bf W}^n\)に 0 or 1の離散変数 \({\bf b}^n\)を掛け合わせる
- \({\bf b}^n\)をゲート変数と呼び, ベルヌーイ分布に従うと仮定
- \({\bf b}^n\)が離散変数なので最適化の際にスムージングが必要になる
- \({\bf b}^n\)をHard concrete distributionに従う確率変数 \({\bf s}^n\)を用いて書き換える
- これにより目的関数のモンテカルロ近似が可能になる
- MIST, CIFAR-10, N-MNIST, GVSジェスチャーデータを使用
- MISTとCIFAR-10についてはピクセル値をスパイク系列に変換して使用
- 提案手法は既存手法と精度では大きな違いはないが早いことを示した
- 学習データを減らした場合も頑健な振る舞い
- スパース制約はフルコネ層より畳み込み層により強く影響する
- 畳み込み層では同じパラメータを何回も使うからだと考察できる
Exploring Self-Supervised Representation Ensembles for COVID-19 Cough Classification PDF
Hao Xue (RMIT University); Flora D. Salim (RMIT University)
イントロ
- 咳はCOVID-19患者の主要な症状の1つ
- COVID-19の診断のために呼吸音を自動的に分類するタスクに取り組む
- 咳の音による診断はスマホアプリ等でできるので, PCR検査や画像診断に比べて比較的手軽
- パンデミック時は, 健康なグループとCOVID-19陽性グループの両方から呼吸音を収集するため, 多くのクラウドソーシングプラットフォームが設計された
- これらのデータセットを用いてCOVID-19の検出を目的とした咳分類モデルが提案されている
- これらの手法は全て教師あり学習
- データのアノテーションにはコストがかかる, プライバシーの問題が発生する
- 本研究では咳分類の自己教師ありモデルを提案する
- 提案手法は(i) Pre-training と(ii) Downstream の二つのフェーズからなる
- まずContrastive learningのためのサンプルを生成
- 生の音声から特徴量を抽出しスライディングウィンドウをかける→同じ長さでクリップ
- 同一の音声から作成したクリップのペアにポジティブ, それ以外のペアにネガティブのラベルを付ける - 後段のContrastive learningではTransformer encoderを使用 (Pre-training)
- ラベルなしデータとラベル付きデータの間での属性の偏りを考え, ランダムマスク付きのTransformer encoderを採用
- その後のDownstramフェーズではCOVID-19の陰性/陽性を出力するアンサンブルモデルを用いる
- CoswaraとCOVID-19という2つの咳の音声データを使用
- Pre-trainingフェーズでは正解ラベルを使用しない
- Pre-trainingではCoswaraデータを用いた
- 提案手法は教師ありモデルと比較して遜色ない分類精度
- Pre-trainingとdownstreamどちらのフェーズでもマスキングが有効
Geometric Graph Representation Learning on Protein Structure Prediction
Tian Xia (Auburn University); Wei-Shinn Ku (Auburn University)
- タンパク質の三次構造の学習は重要
- NMR, X線結晶構造解析等の実験は時間がかかり, コストが高くつく
- アミノ酸の系列がタンパク質の三次構造を決める
- 系列からの三次構造の決定は生物学における重要なタスクだが, いくつか課題がある
- タンパク質は単純な分子に比べて多数のアミノ酸を含む&アミノ酸が特殊な構造を持つ
- 通常の畳み込みNNは画像の各ピクセルの近隣を見る→アミノ酸の系列は配列上離れているものでも隣り合わせになることがある
- 長さが異なる
- 三次構造のグラフを2XSEで表す
- エッジの有無を表す行列に加え, 接続の角度を表す変数 \(\phi\), \(\psi\)を導入
- アミノ酸の系列グラフ \(G=(\texttt{V},\texttt{E},E,F)\)を入力, タンパク質の三次構造 \(G=(\texttt{V},\texttt{E}',E',F')\)を出力するモデルを学習
- 提案手法はedge translation pathとnode translation pathからなる
- Edge translationはエッジとノードの特徴量を入力に取り全ての残基のペアの距離を出力
- 通常の畳み込みと長距離の依存関係を考慮したedge2edge畳み込みの二つを使用
- Node translationはペアの距離とノード特徴量を入力として取り, タンパク質グラフの全てのノードの角度 \(\phi\), \(\psi\)を出力するMPNN
- Edge translationはエッジとノードの特徴量を入力に取り全ての残基のペアの距離を出力
- 上記2つのpath各々についての損失関数の和で目的関数を定義
- 5つのデータを使用
- Edge translationの誤差, node translationの誤差を評価
- どちらも提案手法が最も良い精度
Identifying Coordinated Accounts on Social Media through Hidden Influence and Group Behaviours PDF
Karishma Sharma (University of Southern California); yizhou zhang (University of Southern California); Emilio Ferrara (University of Southern California, USA); Yan Liu (USC)
イントロ
- ソーシャルメディアの濫用による世論操作が問題になっている
- 2016年の米大統領選においてはロシアのメディア IRAによる偽情報の流布で選挙結果が左右されたと言われている
- メディアの操作にはしばしば組織的なアカウントが使われる
- 組織的なアカウントの特定は偽情報の流布を防ぐ上で重要なタスク
- アカウントの特徴や偽情報の宣伝への参加などの行動や, 時間的に同期した活動などの集団の行動に基づいてクラスタリングを行う手法が提案されている
- これらの手法は未知のアカウントに対する判定ができないという課題がある
- また, 時間的に同期した活動は組織的なアカウント以外にもよく見られるので, 誤判定も多い
- 本研究では隠れたアカウント間の関係と協調的な行動を考慮したモデルを提案
- 教師なしの生成モデルを提案
問題設定
- ソーシャルネットにおける活動の履歴 \(C_s=[(u_1,t_1),(u_2,t_2),...,(u_n,t_n)]\)を入力とする
- ここで \((u_i,t_i)\)はアカウント \(u_i\)の時刻 \(t_i\)における活動 (投稿, シェア, リプライなど)
- Masked self-attentionでアカウントを埋め込み, Temporal difference encodingを用いて直近の履歴を埋め込み
- これらの埋め込みベクトルを入力とするMixture density networkで強度関数をモデル化
- 埋め込みベクトル \(c_i\)の変換で定義した重み \(w_i\), 平均 \(\mu_i\), 分散 \(s_i\)の混合ガウス分布でイベントの発生確率をモデル化
実験
- 正解ラベル付きのIRAデータを用いてアカウントの特定精度を定量的に評価
- 既存の教師なし手法を大きく上回る精度
- 教師あり手法の精度はやや下回る
- 定性評価ではTwitterでCOVID-19関連のつぶやきを収集し提案手法で協調的アカウントを特定
- 特定されたアカウントについてそれらのアカウントによる投稿に含まれるハッシュタグをランキング
- 協調的アカウントは他のアカウントに比べ, NoMask, NoVacctine, ビルゲイツに関する陰謀論を積極的に宣伝していることがわかった
Interpreting Internal Activation Patterns in Deep Temporal Neural Networks by Finding Prototypes
Sohee Cho (KAIST); Wonjoon Chang (KAIST); GINKYENG LEE (UNIST-SAIL); Jaesik Choi (KAIST)
JOHAN: A Joint Online Hurricane Trajectory and Intensity Forecasting Framework
Ding Wang (Michigan State University); Pang-Ning Tan (MSU)
- 台風の軌跡と大きさの予測は被害を抑える上で重要
- 軌跡の予測精度は年々改善されているが大きさの予測についてはまだ改善が必要
- 先行研究は過去の履歴を使うもの, 未来の気象データを使うもの, 物理モデルの出力を使うものの3つ
- ほとんどが軌跡の予測のための手法
- また, バッチ学習に基づくもので非定常データには適さない
- 台風が継続的にトラッキングされている状況では直近の軌跡を参考にモデルをアップデートできる手法が望ましい
- 本研究では台風の軌跡と大きさを同時に予測するタスクに取り組む
- 台風の軌跡と大きさは関係している (最寄りの海岸線までの距離と台風の大きさの間に強い相関)
- 台風の位置の情報を大きさの予測時に考慮することで精度が上がると考えられる
- また, 台風の大きさだけでなくそのカテゴリを予測する必要がある
- 大型の台風ほど予測が必要な一方で, そのような台風ほどデータが少ないクラスインバランスの問題がある
- 目的関数を軌跡予測の誤差 \(\mathcal{L}_{tra}\)と大きさ予測の誤差 \(\mathcal{L}_{int}\)の和で定義
- 大型に分類される台風に重み付けするための分位点パラメータ \(\xi\), \(\tilde{\xi}\)を導入
- ハイパラとして与えるがオンラインで自動更新する
- \(\xi\), \(\tilde{\xi}\)は台風の位置 \(y\), 大きさ \(z\)の関数として設計するが, \(y\), \(z\)の観測がない場合は予測値 \(\tilde{y}\), \(\tilde{z}\)を代わりに使う
- 予測誤差 \(\vert y-\tilde{y} \vert^2\)を予測が上ぶれする場合と下ぶれする場合に分けてそれぞれに重み \((1-\xi)\), \(\xi\)を掛け合わせる
- 時刻 \(t\)における \(\tau\)タイムステップ後の予測の重要度を表すパラメータ \({\bf w}^{t,\tau}\)を導入しこれをオンラインで自動更新する
- 2つの台風データを用い, 台風の軌跡と大きさの予測精度を MDE, MAE, F1スコアで評価
- 台風ごとの \({\bf w}\)の変遷を可視化し台風ごとに異なる値が学習されていることを示した
Knowledge is Power: Hierarchical-Knowledge Embedded Meta-Learning for Visual Reasoning in Artistic Domains
Wenbo Zheng (Xi’an Jiaotong University); Lan Yan (Chinese Academy of Sciences); Chao Gou (Sun Yat-Sen University); Feiyue Wang (Chinese Academy of Sciences)
- Visual reasoningは視覚的質問応答
- 複数の絵と質問文が与えられた下で質問への回答を生成する
- 例えばモネの「印象・日の出」とヴァン・ダイクの「チャールズ一世騎馬像」を提示され, 印象派の名付け親は? (答えはルイ・ルロワ) 甲冑を着ているのは? (チャールズ)といった質問に答える
- 絵画はキュビズム, リアリズム, シンボリズム, 印象派といった様々な流派がある
- 既存の深層学習はリアリズムについての有効性は広く知られているが, 例えばキュビズムに適用できるかは定かでない
- また, 本タスクにおいては文脈や画家の情報が必要だが, 既存の質問応答システムはこれらの外部情報を考慮していない
- 本研究では絵画と質問文の関係をメタラーニングで学習するアプローチを提案
- さらに文脈を考慮するため外部情報を埋め込み特徴量を結合する
LawyerPAN: A Proficiency Assessment Network for Trial Lawyers
Yanqing An (University of Science and Technology of China) et al.
- 習熟度の評価は様々な応用で重要
- 法定弁護士の習熟度を評価するタスクに取り組む
- 弁護士は異なる専門領域において異なる習熟度を持つ
- 弁護士の習熟度の評価は弁護チームのメンバーを選定する上で役に立つ
- その際, 以下が課題になる
- 専門性の評価尺度がない
- 裁判の結果は一人の弁護士によるものではなくチームの弁護士や状況にも依存する
- 裁判の結果は事件の特徴による
- 本研究では項目応答理論 (IRT)に基づくモデルを提案する
- 生徒が特定の質問に正しく回答する確率 \(\theta\)をその質問の難しさ \(\beta\)と識別可能度 \(\alpha\)を用いて \(\theta=1/(1+e^{-D\alpha (\theta-\beta)})\)でモデル化する
- 弁護士がある裁判の結果に対してプラスに働く確率 \(P(\theta)\)を \(P(\theta)=1/(1+e^{-Q\cdot (Max\Theta-Min\Theta)(\theta-\beta)})\)
- \(Q\)はケースと法的領域の関係を表すバイナリ行列 (手動で与える)
- \(\Theta\)はチームに参加する弁護士の習熟度
- \(\theta\)と \(\beta\)については二通りのモデル化を検討
- \(\theta\)は弁護士の習熟度で \(\beta\)はケースの難しさ
- \(\theta\)は弁護側チームの習熟度で \(\beta\)は原告側の習熟度
- 学習にはケースの履歴 \(G_J\)と記述 \(D_J^W\), \(Q\)行列を用いる
- 予測時は裁判ログ \({\bf R}: R_{ij}=(l_i,c_j,y_{ij})\)と行列 \(Q\)が与えられた下で各々の領域における弁護士の習熟度を推定する
Learning Process-consistent Knowledge Tracing
Shuanghong Shen (University of Science and Technology of China) et al.
- オンライン学習等における生徒の知識レベルのトレースは学習のパーソナライズなどにおいて重要
- 既存のアプローチではとある問題に正答できるか否かで知識レベルを判断する
- そのため間違いがあった場合に知識レベルがどんどん下がっていく様が学習されるが, これは現実に即していない
- 不正解は学習において自然な要素であり, 間違いから学ぶこともある
- 知識レベルを表す潜在ベクトル \({\bf l}_t\)を導入しその時間変化時系列NNでモデル化
- 時刻 \(t\)に新たに得られる知識 \({\bf l}_{t}\)が前の時刻の知識 \({\bf l}_{t-1}\)の非線形変換で決まる
- 現在の知識をこれまでの知識 \({\bf l}_{t-1}\)と \({\bf l}_t\)の和 \(\times\)忘却率で表す
- 最後に現在の時刻に基づいて正答率を予測
- 3つのパブリックデータを使用
- 生徒の正答率の予測タスクにおいて既存手法を上回る精度
- 提案手法はデータが不完全な場合にもロバストな予測
- 定性評価では個人の学習トレースを可視化
- 学習の過程で (例え回答を間違えたとしても)知識を獲得していく様子を推定できている
Learning to Recommend Visualizations from Data PDF
Xin Qian (University of Maryland, College Park) et al.
イントロ
- 可視化の自動化に取り組む
- 既存の可視化推薦手法は予め決められたルールに基づくものであり, いくつか問題がある
- まず, これらの手法には品質上の問題があり, 推奨される可視化の実用性や有用性が制限されることがある
- 第2に, 手動で定義されたルール/ヒューリスティックのセットを使用してビジュアライゼーションをスコアリングした場合, 多くのビジュアライゼーションが完全に同じなスコアを得ることになる
- 第3に, これらの手法に追加のルールを加えることは面倒で, 時間と労力がかかる
- 最後に, ユーザの好みの変遷に追従することができない
- 最近は機械学習ベースの可視化推薦手法も提案されているが, End-to-endの手法は存在しない
- 本研究では, ユーザによって作成された可視化データに基づき, 深層学習を用いて可視化の推薦を行うアプローチを提案する
- 本研究の一つ目の貢献は問題の定式化
- plot.ly等の可視化データをモデルの学習時に使う
- あるデータセットに対して可視化を生成しスコアをつける
- このタスクは可視化に使う特徴量の部分集合の推定と可視化のデザインの推定という二つのサブタスクに分けられる
- 学習データに含まれる可視化結果を正例として用いる
- 学習データに含まれない可視化をサンプリングし負例として扱う
- 学習データに含まれない可視化は様々あるので効率的なサンプリングが必要
問題設定
- 学習ではデータセット \({\bf X}_i\)と可視化 \(\mathbb{V}_i\)の組からなるコーパス \(\mathcal{D}= { ({\bf X}_i,\mathbb{V}_i) }_{i=1}^N\)を使用
MapRec: Map-Constrained Trajectory Recovery via Seq2Seq Multi-task Learning
Huimin Ren (Worcester Polytechnic Institute)
- GPS軌跡を用いた応用はナビや旅行時間の推定, 運転行動の分析など様々
- これらの応用においては密な軌跡が必要だが, そのような軌跡の取得は難しい
- スパースなGPSデータから密な軌跡を再構成するタスクに取り組む
- 既存手法は内挿+マップマッチングという2つのステップからなる
- 本研究ではこれをEnd-to-endで行う手法を構築する
- その際, 道路ネットワークの制約のもとで軌跡の生成を行う必要がある
- グリッドを粗くするとノイズが増える
- さらに, 道路状況は様々な要因に影響される
- 提案手法はMulti-task learning, Constraint mask layer, Attentionの3つのモジュールからなる
- Constraint mask layerでは道路と観測点の距離を測る関数を定義
- 距離が近いペアには1, 遠いペアには0を入れた行列で入力をマスクする
Mitigating Performance Saturation in Neural Marked Point Processes: Architectures and Loss Functions PDF
Tianbo Li (Nanyang Technological University); Tianze Luo (Nanyang Technological University); Yiping Ke (Nanyang Technological University); Sinno Pan (NTU, Singapore)
- 属性付きイベント系列は実世界において最も一般的なデータの一つ
- このようなデータは時刻と属性を含む
- 金融取引, 自然言語, 森林における木々同士の空間相関など様々な応用で取得される
- このようなデータのモデル化にはマーク付き点過程が広く使われている
- マーク付き点過程の柔軟性を上げるため, RNN等のニューラルネットと組み合わせるアプローチも提案されている
- 最近の研究ではアテンションモデルの導入が提案されている
- その他, グラフベースのニューラルネットをHakes過程に導入するアプローチもある
- これらの手法は既存の点過程より柔軟ではあるが, 実際のイベント系列のモデル化に足るものかどうかはわからない
- 上述のモデルはニューラルネットを使っているとはいえ, 強度関数の関数形にある程度の仮定を置いている
- 本研究では事前の分析でニューラルネットを複雑化していくとどこかで精度が飽和するということを示した
- 構造と損失関数の2つを改善した新たなニューラルマーク付き点過程を提案する
Model-Agnostic Counterfactual Reasoning for Eliminating Popularity Bias in Recommender System PDF
Tianxin Wei (University of Science and Technology of China) et al.
- 実世界の推薦システムは, 学習データとテストデータが独立同一分布でない (non-IID)リアルタイムのユーザ相互作用に基づいて継続的に学習・更新される
- 図1は, 実世界のAdressaデータセットにおいて, 標準MFとLightGCNを学習し, 全ユーザの上位 \(K\)個の推薦リストに含まれるアイテムの頻度をカウントし, 人気バイアスの存在を示したもの
- 青線は実在する非IIDテストデータセットのアイテム頻度
- 見ての通り, 学習データの中で人気の高いアイテムが頻繁に推薦されており, 深刻な人気バイアスがかかっている
- このようなpopularityバイアスはMatthew効果を生む
- このような課題に対処するため, ロングテールの商品を重視する推薦手法が提案されている
- しかし, これらの手法は, 商品の人気度が各特定の相互作用にどのように影響するかを細かく考えたり, 人気度の偏りのメカニズムを体系的に捉えることができない
- 本研究ではPopularityバイアスを因果推論の観点から解析する
- まず, 推薦プロセスにおける重要な因果関係を記述するために, 因果関係グラフ (図2c)を作成
- 既存の推薦手法では, ユーザ-商品間の相互作用の発生確率 \(Y\)に影響を与える要因としてユーザと商品のマッチング \(K\)のみを考慮 (図2a)
- 本研究ではユーザーと商品のマッチング \(K\)に加え, 商品の人気 \(I\), ユーザーの適合性 \(Y\)が相互作用の発生確率 \(Y\)に影響すると仮定
- 反事実的推論の理論によると, ユーザーとアイテムのマッチングが破棄され, アイテムの人気とユーザーの適合性によって相互作用が生じる世界を想像することで, \(I \rightarrow Y\)の直接的な因果を推定することができる
- Popularityバイアスの評価を行うためには, 全体のランキングスコアから反事実世界でのランキングスコアを差し引けばよい
- 本研究では, この理論に従ってpopularityバイアスの推定を行い, それを考慮して推薦を行うアプローチを提案する
- \(U\rightarrow I\), \(I\rightarrow Y\)の効果を捉えるための2つの補助タスクを構築
Model-Based Counterfactual Synthesizer for Interpretation
Fan Yang (Texas A&M University); Sahan Alva (Texas A&M University); Jiahao Chen (JPMorgan AI Research); Xia Hu (Texas A&M University)
Modeling Context-aware Features for Cognitive Diagnosis in Student Learning
Yuqiang Zhou (University of Science and Technology of China) et al.
- Context=個人の学習習慣, 自宅学習の環境など
- 認知診断=知識の習得度などの認知状態を推定すること
- 認知診断はその重要性から様々な手法が提案されているが, contextを考慮するものはあまりない
- 教育学の分野においてはcontextの重要性が指摘されている
- 学習におけるcontextは様々あり, それらの影響は個人によって違う
- 同じチュータリングをしても怠け者の生徒より頑張り屋さんの生徒に影響が出やすい
- また, context間にも相関がある
- 裕福な家はチューターを頼みやすい
- 生徒の学習ログ \({R_q, R_e}\)に基づいて知識の習熟度 (テストの正答率)を予測
- \(R_q\)はテストのログ, \(R_e\)は練習問題のログ
- 提案手法はeducational context modelingとdiagnosis enhancementの二つのステージからなる
- context間の関係性をモデル化するためにattentionを使う
- 実験ではPISAデータを3地域に分けて使用
- contextの重要度を表すパラメータ \(d_t\)を可視化
- 最後に各contextの重要度を国別に示す
- HOME ESCS, ICT Usageがどの国でも重要
- 韓国, 中国では両親の教育の重要度が高い
- アジアとそれ以外で傾向が違うのは直感に合った結果
MULTIVERSE: Mining Collective Data Science Knowledge from Code on the Web to Suggest Alternative Analysis Approaches
Mike A Merrill (University of Washington); Ge Zhang (Peking University); Tim Althoff (University of Washington)
- データサイエンティストの知識のレベルや幅は様々ある
- シンプルなタスクでも, 前処理の仕方, モデルの選択, 分布の選択, 考慮する潜在因子などで分析結果が変わる
- 分析方法の決定時には複数の判断ポイントがあると考えられる
- そしてこういった決定ポイントはコードの中に含まれている
- 例えばとあるデータを前処理してSVMで分類するコードでは, \(\texttt{dropna()}\)と \(\texttt{svm.fit(train)}\)を含む行が決定ポイト
- データ分析のためのコードをより有効かもしれない別のコードに変更する生成タスクを考える
- まず修正を加えるべき決定ポイントを特定するため, 各行が決定ポイントに含まれるか否かの分類を行う
- その後各決定ポイントについて代わりのコードを生成する
- 例えば \(\texttt{svm.fit(train)}\)を \(\texttt{KNN.fit(train)}\)に変更するなど
- こういったモデルの学習を行うため, Kaggleからデータを集めてきてコーパスを作る
- 複数のバージョンを取ってきて各々のdiffを取る
- 単純な変数名の変更, 出力場所の変更, 空白の削除など本質的でない変更を除去
- 残りの変更箇所を決定ポイントとする
- 単語レベルのdiffを取り, 変更されている単語を決定ポイントとする
- 新しい方の単語を古い単語の修正候補とする
- BERTと同様, エンコーダとデコーダからなるSeq2seqモデルを構築
- まずエンコーダに単語列 \({\texttt{svm . fit ( train ) }}\)を入力
- エンコーダでは決定ポイントか否かを出力
- デコーダは単語列を入力として修正案 (例えば \({\texttt{KNN . fit ( train ) }}\))を出力
- その際, 決定ポイントについてのみ修正を出力する
- こういったSeq2seqモデルの精度を向上させるため, pythonパッケージの依存関係を利用
- sklearnなどのPythonパッケージのクラスの依存関係をグラフで表す
- グラフの結合関係を反映するようなノード (クラス)の埋め込みベクトルを学習
- 実験では決定ポイントの分類, 修正案の出力というそれぞれのタスクについて精度評価
- 決定ポイントの分類においては既存手法と変わらない精度
- 修正案の出力については既存手法を上回る精度
- 決定ポイントのみで評価しても同様の結果
- PhDレベルのデータサイエンティスト5人に修正案の評価を依頼
- 提案手法による修正案50個と既存手法による案50個を提示
- Syntax, reasonableness, sementic acceptanceという三つの基準で評価してもらい, 全ての基準で既存手法よりよい評価を得た
Neural-Answering Logical Queries on Knowledge Graphs
Lihui Liu (University of Illinois at Urbana-Champaign) et al.
NewsEmbed: Modeling News through Pre-trained Document Representations PDF
Tianqi Liu (Google); Jialu Liu (Google Research); Cong Yu (Google)
- ニュース記事のモデル化 (クラスタリング, トピック分類)は重要なタスク
- ニュース記事の文章をベクトルに埋め込む手法が主流
- 文章の埋め込みのための手法として, bag-of-words, トピックモデルなどが提案されている
-文章を疎な単語ベクトルで表現
- 単語間の類似性は考慮しない
- Word2Vec, GloVe, FastTextなど密なベクトル表現が可能なモデルが開発
- 文字や単語の共起を捉えることができる
- CNN, RNN, Transformerの適用も進んでいる
- 最近は自己教師付き学習, 教師なし学習, 転移学習の発展に伴い, BERT, T5, GPT3など事前学習のための手法が提案されている
- ウェブ上の文章を活用
- 膨大なラベル付きデータを使う必要がなくなってきている
- とはいえ, 高精度な分類を行うためにはfine-tuningのためのラベル付きデータが必要
- 文単位では, Universal Sentence Encoder (USE)やSentence-BERT (SBERT)が高い性能を示している
- ただしこれらは文ごとの分類について評価を行なったもので, 長い文章に対する性能は確かめられていない
- また, out-of-vocabulary (OOV)は依然として課題
- 異なるドメインの知見を活用することで特定のドメインにおけるタスクの精度が上がることがドメイン適用の研究で確かめられている
- このアイデアをニュース記事のモデル化においても適用
- 他言語の知見を使うことを考える
- 本研究ではまず, 数十億の多言語文章トリプレット (アンカー, ポジティブ, ネガティブ)を取得
- アンカーとポジティブな文書は意味的に近い
- アンカーとネガティブな文書は関連性はあるがより類似性が低い
- トリプレットニューラル構造を用いたモデルを構築
Physical Equation Discovery Using Physics-Consistent Neural Network (PCNN) Under Incomplete Observability
Haoran Li (Arizona State University); Yang Weng (Arizona State University)
Popularity Bias in Dynamic Recommendation PDF
Ziwei Zhu (Texas A&M University); Yun He (Texas A&M University); Xing Zhao (Texas A&M University); James Caverlee (Texas A&M University)
- Popularityバイアスは推薦システムにおける長年の課題
- Popularityバイアス=人気の商品ばかり推薦される
- Popularityバイアスを緩和するための多くの手法は静的な設定を仮定している
- すなわちバイアスの変遷を考慮していない
- 本研究では動的な推薦におけるPopularityバイアスを考える
- 動的推薦システムではユーザの行動 (クリック, レーティング)をシステムにフィードバックして推薦システムを更新する
- このようなフィードバックのループの中では, 以下の要素がpopularityバイアスに寄与すると考えられる
- inherent audience size imbalance
- model bias
- position bias
- closed feedback loop
- これらの4つの要素を念頭に置きつつ, 本論文では以下のリサーチクエスチョンを設定
- Q1) Popularityバイアスが同時間発展するか?
- Q2) 4つの要素がバイアスにどう影響するか?
- Q3) 要素の相殺によってpopularityバイアスを緩和できるか?
- 静的なバイアスを仮定する従来手法では人気商品・不人気商品の推薦回数が問題になるが, 本研究の設定においては人気商品・不人気商品のクリック回数が問題になる
- 本研究は以下の3つのパートからなる
- シュミレーションを行い, Q1, Q2を検証
- 動的な推薦においてバイアスを軽減する方法を提案
- 提案手法が既存の静的バイアス除去法に比べて有効なことを実験で確かめた
PcDGAN: A Continuous Conditional Diverse Generative Adversarial Network For Inverse Design PDF
Amin Heyrani Nobari (MIT), Wei Chen, Faez Ahmed
Probabilistic and Dynamic Molecule-Disease Interaction Modeling for Drug Discovery
Tianfan Fu (Georgia Tech), Cao Xiao, Cheng Qian, Lucas Glass, Jimeng Sun
PURE: Positive-Unlabeled Recommendation with Generative Adversarial Network
Yao Zhou (University of Illinois at Urbana-Champaign) et al.
- 推薦の重要性は日々増している
- 推薦システムはデータ収集, モデルの学習, モデルの適用という3ステップからなる
- ユーザ-アイテムデータのうちラベルがないものの中に負例が含まれる
- ユーザ-アイテムの相互作用だけでなく, 観測されたユーザやアイテムも真の関係を反映している
- 提案手法ではユーザは正例のみを観測できるとし, 残りの商品をラベルなしと見做す
- ランキングモデルの性能を上げるためフェイクなユーザ・商品を生成するモデルを構築
- 観測データからのサンプルを正例, それ以外からのサンプルをラベルなしとし, Positive-unlabeledサンプルのための目的関数を使用
- Movielens, Yelpの二つのデータを使用
- 5カテゴリの既存手法と比較し, 提案手法が既存手法の精度を大きく上回っていることを示した
- スケーラビリティの評価, ablation studyも実施
Socially-Aware Self-Supervised Tri-Training for Recommendation PDF
Junliang Yu (University of Queesland) et al.
- Self-supervised learning (SSL)が様々な分野で注目を集めている
- SSLは教師なし学習の一種で, ラベルを利用せず, 入力データ自体から教師データを作り出す
- グラフ表現学習においてもSSLの有効性が確かめられている
- エッジを消す, ノードをマスク or シャッフルする等の摂動を加え, 変更後のグラフと元のグラフのノード特徴量の差異を最大化する手法 (graph contrastive learning)
- 少数だが, 推薦タスクへの適用も検討されている
- 推薦タスクにおいては, ただのグラフと違い, ユーザ/アイテム同士の同類性を考慮する必要がある
- 既存のグラフグラフ表現学習では, 対応するノード間の差異のみを見る
- そのため, それ以外のノードはネガティブサンプルとして働く
- 異なるノード間に同類性がある場合, モデルの性能が下がってしまう
- 本論文ではtri-trainingとSSLを組み合わせた手法を提案
- ユーザ同士の同類性を考慮するため, ユーザ間の関係性を考慮
Spatial-Temporal Graph ODE Networks for Traffic Flow Forecasting PDF
Zheng Fang (pku); Qingqing Long (Peking University); Guojie Song (Peking University); Kunqing Xie (PKU)
- 交通流予測に取り組む
- 交通流の予測においては場所間の地理的相関と意味的相関を考慮する必要がある
- また, 交通流の時系列は幅広いパターンを持つ
- 交通流予測においては近年, GNNがよく使われている
- GNNとRNNを組み合わせた手法も提案されている
- ただし, 既存手法にはいくつか課題がある
- 時間相関と空間相関を独立に扱っている
- GNNはレイヤー数を深くしていった場合にover-smoothing (全てのノードが同じような値に収束していく)の問題が生じる
- 本研究では Spatial-Temporal Graph Ordinary Differential Equation Network (STGODE)を提案
- 場所間の意味的相関と地理的相関の両方を考慮するため, 2種類の隣接行列を構築する
- Over-smoothingの問題を緩和するため, residual connectionsを使うことを考える
- Residual connectionsはODEの離散化と見做せることから, continuous graph neural network (CGNN)を採用する
- 時間パターンと空間パターンを同時に扱い時空間相関をモデル化するため, 時空間テンソルを構築する
Table2Charts: Recommending Charts by Learning Shared Table Representations PDF
Mengyu Zhou (Microsoft Research)
イントロ
- 表で表された多次元データからのチャートの作成は教育, 研究, エンジニアリング, 金融など様々な分野で一般的に行われている
- その際, まずどのデータを使うかを選び (データの照合), その後どう可視化するか (デザインの選択)を決める
- チャートの作成にはデータ分析と可視化ツールに関する経験・知識が必要
- チャートの作成を自動化する手法はいくつかある
- これらの手法はよく使われるチャートの種類 (折れ線グラフ, 棒グラフ, 散布図)をランク付けして推薦するもの (マルチタイプタスク)
- あまり使われているわけではないが意味があるチャートの種類 (レーダーチャートなど)を1つ推薦するタスク (シングルタイプタスク)には適用できない
- シングルタイプ, マルチタイプの2つのタスクにおいてデータの照会とデザインの選択の両方を行う場合, 以下の3つの課題がある
- マルチタイプのタスクとシングルタイプのタスクのモデルを繰り返し独立して設計・学習・利用することは, メモリとスピードの両面で非効率
- データが不均衡. 4つの主要なチャートの種類 (折れ線グラフ, 棒グラフ, 散布図, 円グラフ)がデータの98.91%を占めているが, それ以外のマイナーなチャート (エリアやレーダー)のデータが少ない
- 表からデータを選択して視覚化する際, データの統計値だけでなく表全体の意味を考慮する必要がある
- 本論文では, 表・チャートのペアからなる大規模データからデータクエリとデザイン選択の両方を含むチャート作成の共通パターンを学習し, 与えられた表ごとにチャートを推薦するTable2Chartsフレームワークを提案
- Web上のデータから165214個の表から作成された266252個のチャートをエクセルファイルで収集
- この大規模コーパスを用いてTable2Chartの有効性を検証
- 各チャートの種類について, シングルタイプ・マルチタイプのタスクにおけるトップ3およびトップ1推薦の精度を評価
- また, 検索数の多い500のWebテーブルを対象に人手による評価を行い提案手法の精度を検証
- 最後にT-SNEによる可視化を行なった
- DQNがマルチタイプタスクの学習中に共有テーブル表現を学習し, 後の伝達学習に役立てることで, シングルタイプタスクの性能を向上させ, メモリ使用量を節約できることを示した
TabularNet: A Neural Network Architecture for Understanding Semantic Structures of Tabular Data PDF
Lun Du (Microsoft Research) et al.
イントロ
- 人にとって理解しやすく可視化された表をシンプルな表に変換
- このタスクはヘッダー領域の検出, セルの役割の分類という2つのサブタスクからなる
- 表形式のデータがどのように構成され, どのように相関しているかを深く理解するためには, 空間情報と関係情報を同時に考慮する必要がある
- 空間情報は統計的情報と領域間の差異の2種類ある
- 同じ行や列のセルは意味的に一貫性があり, そこから平均値, 範囲, データタイプなどの統計情報を抽出することができる
- また, ほとんどの表には, ヘッダ領域とデータ領域という2つの異なる領域がある
- 関係情報はセル間の階層的な関係や傍系的な関係など
- 本論文では, 表形式のデータの空間情報と関係情報を同時に捉えることができる新しいニューラルネット TabularNetを提案
- 表形式のデータを行列, グラフに変換し, それぞれに演算をかける
- 行列表現から空間情報を抽出するため行/列レベルのPoolingとBi-GRUをかける
- 表からグラフへの変換にはWordNetのグラフ構築アルゴリズムを適用
- 階層的・傍系的な関係を学習するため, 構築したグラフにGCNをかける
- TabularNetの有効性を検証するため, 実世界の2つのスプレッドシートデータを用いて, セルの役割分類とヘッダの検出という2つの意味構造理解タスクを実施
- TabularNetはTransformerなど最新の既存手法を上回る精度
- マルチタスク設定においても有効
Temporal Graph Signal Decomposition PDF
Maxwell J McNeil, Lin Zhang, Petko Bogdanov
- Temporal graph signalは固定のネットワーク構造と時間パターンを持つ
- 例えば交通流の例だとノードがサンサー, エッジが道路
- タンパク質の相互作用ネットワーク上の遺伝子発現, ソーシャルメディア上の活動, センサーネットワーク等もtempopral graphに含まれる
- このようなデータはネットワーク構造を表す隣接行列とノードの値の変化を表す行列 \({\bf X}\)で表される
- センサーによる観測が不安点な場合,内挿が重要なタスクになる
- ソーシャルネットワークにおいてユーザの活動からコミュニティを検出するといったタスクも考えられる
- このようなデータのモデル化には様々なアプローチが用いられている
- 行列分解はネットワーク構造や時間変化の事前知識を入れることができない
- ウェーブレット解析など時間辞書変換はネットワーク情報を利用することができない
- グラフの辞書変換は時間に関する知識を入れることができない
- 本研究ではこれらの手法の強みを組み合わせた手法を提案する
- まずデータ行列 \({\bf bX}\)を \({\bf bX}=\Psi Y W \Phi\)のように分解する
- \(\Psi\)は時間辞書, \(\Phi\)はネットワーク辞書
- \(Y\), \(W\)が時間辞書の変換, グラフ辞書の変換のためのパラメータ
- 既存の行列分解手法と同じ要領でパラメータ \(Y\), \(W\)を学習する
- 欠損値の補完, 時間的内挿, コミュニティ数の推定, コミュニティの検出, 期間の検出といったタスクにおいて提案手法の精度を評価する
TopNet: Learning from Neural Topic Model to Generate Long Stories
Yazheng Yang (Zhejiang University); Boyuan Pan (Zhejiang University); Deng Cai (Zhejiang University); Huan Sun (Ohio State University)
- 短い記述から長い物語を生成するタスク
- ニュースの自動生成, 議事録生成, 年次報告などの応用
- 既存手法はSeq2seqとSkeletonの二つ
- SkeletonがSOTAの精度を達成しているが, いくつか課題がある
- ラベル付けが必要
- 頻度に基づいて単語の抽出を行うため多様性に欠ける
- データにドメイン特有のバイアスが含まれており, ドメイン適応が難しい
- 本研究では教師なし, 文章からのトピック抽出, coherentの考慮がどの程度性能に効くか調査
- Neural topic modelとTransformerからなるモデルを提案
- 実験では2つのデータを使用
- 提案手法は既存手法に比べて高い文章生成の性能
Towards a Better Understanding of Linear Models for Recommendation PDF
Ruoming Jin (Kent State University); Dong Li (Kent State University); Jing Gao (iLambda); Zhi Liu (iLambda); Li Chen (iLambda); Yang Zhou (Auburn University)
イントロ
- 推薦のための手法は回帰, 行列分解, 深層学習ベースのアプローチ等様々なものが提案されている
- しかし, これらの手法はSLIMやEASEなどの線形モデルと比べて精度が出ないことが最近の研究でわかっている
- SLIM, EASEはユーザ-アイテム行列 \(X\)とアイテム同士の類似度行列 \(W\)の行列積 \(XW\)が \(X\)をうまく再現するような \(W\)を学習するもの
- このモデルはシンプルな線形オートエンコーダと一致 (この時 \(W\)はエンコーダとデコーダを兼ねる)
- \(W\)は行列分解のユーザベクトル, アイテムベクトルに比べて通常サイズが小さいため, 回帰モデルはあまり柔軟性がない
- しかし, 直感に反して精度が出ている
- これらのモデルを低ランク回帰モデルと呼ぶ
- この論文ではまず, こうした回帰モデルがなぜうまくいくか分析した
- 2つのベーシックな低ランク回帰モデルと行列分解モデルを分析し, どちらの手法もユーザーアイテム相互作用行列の特異値をわずかに異なるメカニズムでスケールダウンしていることを明らかにした
- 低ランク回帰は, 行列分解に比べて, ユーザーアイテム行列 \(X\)のより多くの主成分 (潜在的な次元)を利用できる
- また, 行列分解法はユーザーとアイテムの両方の潜在因子行列を用いているためより多くのモデルパラメータを持っているように見えるが, 実際には単純な問題に対する最適解はアイテム行列にのみ依存していることがわかった
- ユーザーとアイテムの相互作用行列の特異値をどのように調整できるかを理解するため, 高次元の連続的な (ハイパー)パラメータ空間を探索できる新しい学習アルゴリズムを導入した
- 提案手法はモデルの学習後にも使うことができる
- それによって, 線形モデルにパラメータを追加し, モデルの精度をさらに向上させることもできる
- このアプローチは筆者の最近の研究 (next-door analysis)と精神が似ているが, 適用先とアプローチが違う
- 本研究は推薦モデルのポストモデルフィッティング探索を対象とした初めての研究
提案手法
- 以下の低ランク回帰モデルを考える
\(W = \text{arg} \text{min}_{rank(W)\leq k}\vert\vert X-XW \vert\vert^2 + \vert\vert \Gamma W \vert\vert^2\)- \(\Gamma\)は \(W\)のフロベニウスノルムに対する制約を決める行列
- このモデルを回帰問題として捉え直す
- この回帰問題はTikhonovの正則化と行列の低ランク近似という二つの部分問題に分けられる
Where are we in embedding spaces? A Comprehensive Analysis on Network Embedding Approaches for Recommender Systems PDF
Sixiao Zhang (University of Technology Sydney) et al.
イントロ
- グラフベースの推薦システムでは, 行列分解に基づくモデルや計量学習に基づくモデルなどの潜在空間モデルが広く用いられている
- ほとんどの潜在空間モデルは, 直感的にわかりやすいユークリッド空間で構築されている
- 従ってこれらのモデルはユークリッド空間の次元によって自由度が制限される
- 特に階層的なデータを埋め込む際は歪みが問題になる
- 歪みに対処するために高次元の潜在空間を考える必要がある
- 最近, 新しい潜在空間として双曲空間が検討されている
- 双曲空間の重要な特性は, ユークリッド空間よりも速く拡大する点
- ユークリッド空間が多項式に従って拡大するのに対し, 双曲空間は指数関数的に拡大する
- ユークリッド空間の円を考えると, 円の中心から離れたところにある多角形は中心に近いところにある多角形よりも小さくなる (図1a)
- 一方, 双曲空間の円として扱うと, どのポリゴンも同じ大きさになる (図1b)
- これは, 同じデータ群を埋め込むためにはユークリッド空間の方が双曲空間よりも必要な空間が大きいことを示唆している
- 双曲面空間のもう一つの重要な特性は, データの階層性を保持できること
- 双曲面埋め込みは現在, 推薦システムにおいて大きな注目を集めているが, どのような状況で双曲面空間を考慮すべきかは明らかでない
- この研究では, 推薦システムのための双曲空間と双曲埋込みに関して包括的な分析を行なった
- まず, 双曲空間とポアンカレ球モデルを紹介
- 次に, 異なるモデル, データセット, および潜在空間の次元における双曲空間の性能に関して3つの仮説を提案
- 最後にメトリック学習に基づく社会的推薦手法であるSocial Collaborative Metric Learning (SCML)と, その双曲空間版であるHyperbolic Social Collaborative Metric Learning (HSCML)を提案
- 推薦タスクの6つのベンチマークデータセットと6つのモデルを用いて仮説を実証的に検証
Why Attentions May Not Be Interpretable? PDF
Bing Bai (Tencent); Jian Liang (Alibaba Group); Guanhua Zhang (Tencent); Hao Li (Tencent Inc); Kun Bai (Tencent Inc); Fei Wang (Cornell University)
イントロ
- モデルの解釈はモデルがどのように意思決定を行うかを説明するもの
- 医療, セキュリティ, 刑事司法など意思決定プロセスの説明責任と透明性が重視される領域において得に重要である
- 式で書くと \(Att(Q,K,V)=Mask(Q,K)\ast V\)
- アテンション機構はモデルの解釈において重要な役割を果たしている
- しかし最近の研究では, アテンション機構で予測された特徴量の重要度が直感的な重要度と必ずしも相関していないことが示唆されている
- 本論文はアテンション機構の解釈可能性を妨げている根本的な原因は組み合わせによる簡略化であると主張
- アテンション結果はマスク \(Mask(Q,K)\)と値 \(V\)の積であるため, マスク自体が \(V\)のハイライト部分以外の余分な情報を含んでいる場合があり, その情報が下流で使われる可能性がある
- 計算されたマスクは, 純粋な特徴の重要性ではなく, 別類の「符号化層」として機能する可能性がある
- 極端な例としては, 2値テキスト分類タスクにおいて, 注意メカニズムは単語の意味に関わらず, ポジティブなサンプルに対しては最初の単語をハイライトし, ネガティブなサンプルについては最後の単語をハイライトすることもできる
- この場合, アテンション層の下流部分では, 最初の単語と最後の単語のどちらがハイライトされているかをチェックすることでラベルを予測することができるが, これでは精度は高くても解釈性が得られない
- 本研究ではまず, 因果効果推定の観点から, 共起的な注意機構と理想的な解釈の違いを理論的に分析する
- 次に構成的な実験によって上述のような組み合わせによる問題が起きうることを示す
- これらの観察結果に基づき, この問題を解決するための方法として, ランダムなアテンションによる事前学習と, マスクに対してニュートラル学習のためのインスタンス重み付けを提案する
Zero-shot Node Classification with Decomposed Graph Prototype Network PDF Site
Zheng Wang (University of Macau); Jialong Wang (University of Macau); Yuchen Guo (Tsinghua University); Zhiguo Gong (University of Macau)
- ノードの分類は, グラフデータ分析において重要なタスク
- 例) 引用ネットワークにおける文書の分類, ソーシャルネットワークにおけるユーザータイプの予測, バイオインフォマティクスにおけるタンパク質の機能識別など
- ごく一部のノードのみがラベル付けされているグラフが与えられるケースを考える
- グラフ構造情報がノード間の相似性を反映していると仮定し, 残りのラベル付けされていないノードのラベルを予測する
- 既存のノード分類手法は新しく生じたラベルを予測することができないという大きな課題がある
- 本研究はノード分類タスクにおいてをゼロショット学習 (ZSL)を行うフレームワークを提案する
- 既存のZSLではラベルごとの意味的記述 (CSDs)を補助情報として用い, 既知のクラスから未知のクラスへ情報の転移を行う
- しかし, クラスが複雑で抽象性が高いグラフネットワークのリナリオにおいてこういった知識の活用は難しい
- また, ノード分類は従来のZSLタスクとは異なり, グラフ構造化されたデータ上で関係性の学習を行う必要がある
- 本論文では, CSDsを自動で取得する手法を提案する
- さらに, 局所性と構成性を考慮した新たな学習手法を提案する
- 多層グラフ畳み込みネットワーク (GCN)の出力を分解する
- 分解された中間表現にいくつかの意味的損失を与えることで局所性を考慮する
- これらの中間表現に重み付き和のプーリング操作を適用し, 対象問題に対するグローバルな表現を得ることで構成性を担保する
What Do You See? Evaluation of Explainable Artificial Intelligence (XAI) Interpretability through Neural Backdoors
Yi-Shan Lin, Wen-Chuan Lee, Berkay Celik
- 機械化学習モデルは様々な応用で役立っているが透明性・説明性に欠けるとの批判もある
- 説明可能なAI (EXplainable AI; XAI)が複数のドメインで提案されている
- 例) CV分野においてはsaliency mapを使って分類に効くオブジェクトを可視化
- 本研究ではXAI手法を大きく二つに分類
- White box: 入力の特徴量の重要度を判断するために微分を使う
- Black box: 入力を色々変えて出力がどのように変わるか確かめる
- XAI分野の課題は評価
- 人手による評価はお金も時間もかかるし不正確な場合がある
- 評価を自動で行う手法は計算時間がかかる
- あるパターン (ここではtrojan triggerと呼ぶ)で入力に変更を加え, 出力がどの程度乱されるか見る
- 画像なら一部を無地の四角で隠してモデルに入力
- パターンの生成にpoisoning attackを使う
- 色, 形, テクスチャなど色々試す
- Triggerを検出できるかどうかでモデルの解釈性を判断
- 提案フレームワークは3つの流れ
- Trojon triggerと学習データ, 評価対象の深層学習モデルからTrojonedモデルを生成する
- テストデータをTrojonedモデルに入力しXAI手法でsaliency mapを推定
- Trajon triggerをGround truthとして3つの評価指標でXAI手法を評価
- 評価基準は
- XAI手法がsaliency mapでtriggerをハイライトできているか
- 検出された領域がミスクラスにつながる重要な特徴量を含んでいるか
- 前者に対しては検出されたsalicency map領域とtrigger領域のoverlapを計算する
- 後者には正しいラベルに分類されたrecovered imageの割合
- IOUの観点からは全ての深層学習モデルに対して普遍的に良いXAIはない
- AlexNetについてはBackpropagationが良いスコア